在介紹了 Hourglass 這個 Heatmap-based 的模型跟 PIPNet 這個 Heatmap-based 結合 Direct 的模型後我們今晚來講講他們的實作! 使用的 Dataset 為之前提到的 WFLW dataset!
我們來實作並訓練 Hourglass 模型用於 Facial landmark 有以下步驟:
首先,我們需要準備一個包含人臉圖像和臉部關鍵點的數據集。假設我們使用的是 WFLW 數據集。數據集的結構應該如下,數據相關資訊如格式等等請參閱我們之前的這一篇:
-- datasets
|-- WFLW
|-- WFLW_images
|-- WFLW_annotations
import torch
import torch.nn as nn
# 定義一個普通常見的 residureblock
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(ResidualBlock, self).__init__()
# Define layers for a residual block
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
# Forward pass of a residual block
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += residual # Residual connection
return out
# 定義 HourglassModule
class HourglassModule(nn.Module):
def __init__(self, num_blocks, num_channels):
super(HourglassModule, self).__init__()
# Create layers for the Hourglass module
self.res_blocks = self._make_residual_blocks(num_blocks, num_channels)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# Create upsample layer
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
def _make_residual_blocks(self, num_blocks, num_channels):
# Helper function to create residual blocks
blocks = []
for _ in range(num_blocks):
blocks.append(ResidualBlock(num_channels, num_channels))
return nn.Sequential(*blocks)
def forward(self, x):
# Forward pass of the Hourglass module
downsampled = self.pool(x)
residual = self.res_blocks(x)
upsampled = self.up(residual)
return upsampled + downsampled
class HourglassNet(nn.Module):
def __init__(self, num_stacks, num_blocks, num_channels):
super(HourglassNet, self).__init__()
self.num_stacks = num_stacks
self.num_blocks = num_blocks
self.num_channels = num_channels
self.entry = nn.Sequential(
nn.Conv2d(3, num_channels, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(num_channels),
nn.ReLU(inplace=True)
)
self.pre_hourglass = nn.Sequential(
ResidualBlock(num_channels, num_channels),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.hourglasses = self._make_hourglasses()
def _make_hourglasses(self):
# Helper function to create hourglass modules
hourglasses = []
for _ in range(self.num_stacks):
hourglass = [HourglassModule(self.num_blocks, self.num_channels) for _ in range(4)]
hourglass = nn.Sequential(*hourglass)
hourglasses.append(hourglass)
return nn.ModuleList(hourglasses)
def forward(self, x):
# Forward pass of the Hourglass network
x = self.entry(x)
x = self.pre_hourglass(x)
outputs = []
for stack in self.hourglasses:
out = stack(x)
outputs.append(out)
x = out # Pass the output to the next stack
return outputs
定義完之後,若你有興趣可以用下以下程式印出模型來看看
# Create an instance of HourglassNet
num_stacks = 1
num_blocks = 4
num_channels = 256
net = HourglassNet(num_stacks, num_blocks, num_channels)
# Print the network architecture
print(net)
結果應該可以成功看到你建構出了 Hourglass 的網路結構 (HourglassNet)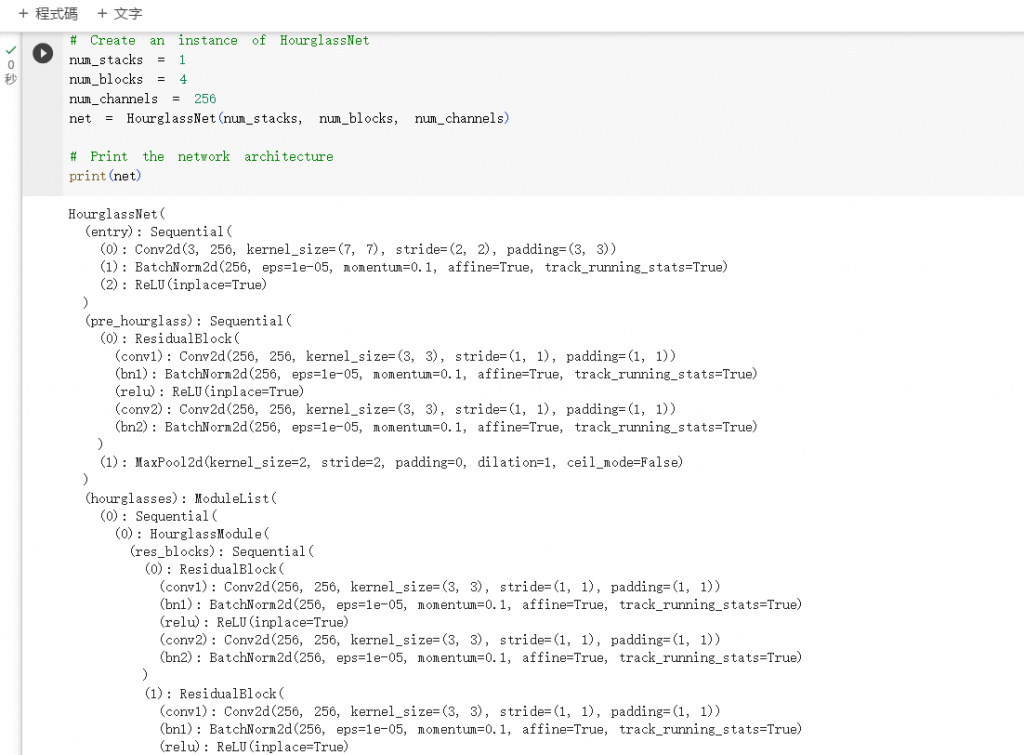
我們需要選擇適合的損失函數。在 Facial Landmark Detection 中,通常使用均方誤差(MSE)作為損失函數,意即 model 預測出關鍵點的 x,y 與 label 的 x,y 相減即可。但今天 Heatmap-based 的方法預測出來的卻是一個熱圖分布,因此我們其實可以用 2D 高斯函數來建構損失函數,意即離中心點越近分數越高,公式如下: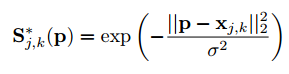
實做起來如下:
def get_peak_points(heatmaps):
"""
:param heatmaps: numpy array (N,15,96,96)
:return:numpy array (N,15,2)
"""
N,C,H,W = heatmaps.shape
all_peak_points = []
for i in range(N):
peak_points = []
for j in range(C):
yy,xx = np.where(heatmaps[i,j] == heatmaps[i,j].max())
y = yy[0]
x = xx[0]
peak_points.append([x,y])
all_peak_points.append(peak_points)
all_peak_points = np.array(all_peak_points)
return all_peak_points
def get_mse(pred_points,gts,indices_valid=None):
"""
:param pred_points: numpy (N,15,2)
:param gts: numpy (N,15,2)
:return:
"""
pred_points = pred_points[indices_valid[0],indices_valid[1],:]
gts = gts[indices_valid[0],indices_valid[1],:]
pred_points = Variable(torch.from_numpy(pred_points).float(),requires_grad=False)
gts = Variable(torch.from_numpy(gts).float(),requires_grad=False)
criterion = nn.MSELoss()
loss = criterion(pred_points,gts)
return loss
def criterion(heatmaps_predict, gts)
all_peak_points = get_peak_points(heatmaps_predict.cpu().data.numpy())
loss = get_mse(all_peak_points, gts.numpy()
return loss
# 假設我們model predict 出來的叫做 heatmaps_predict, label 的叫做 gts.
loss = criterion(heatmaps_predict, gts)
現在,我們可以開始訓練 Hourglass 網絡。這個部分的代碼可能會比較長,包括數據加載、模型初始化、優化器設置、訓練迴圈等。這裡提供一個簡單的示例:
import torch.optim as optim
# Initialize the Hourglass network
net = HourglassNet(num_stacks=4, num_blocks=2)
# 定義 optimizer
optimizer = optim.Adam(net.parameters(), lr=0.001)
# Training loop
for epoch in range(num_epochs):
for batch_data, batch_labels in dataloader: # 使用我們之前介紹的 WFLW 所建立出來的 dataloader
# Forward pass
outputs = net(batch_data)
# Compute the loss
loss = criterion(outputs, batch_labels)
# Backpropagation and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
當 Hourglass模型訓練完成後,你可以使用它來進行推論。這裡只提供一個簡單的示例:
# Set the model to evaluation mode
net.eval()
# Load an input image (you need to define how to load an image)
input_image = load_image("test_image.jpg")
# Perform inference
with torch.no_grad():
predicted_heatmap = net(input_image)
# 有了 `predicted_heatmap` 之後,我們在使用之前定義的 get_peak_points 去得到最終的 landmark points 即可!如有需要可以畫在原圖上 visaulaize!
predicted_landmarks = get_peak_points(predicted_heatmap)
經過這麼多次的實作之後,相信大家大概知道了同一個 task 其實在換模型時只有 model 定義、loss、還有預測後處理比較常會改變,那我們就不重複造車子,只講關鍵改變的地方就好,完整程式可詳閱原始作者釋出的程式:
我們使用 resnet18 當作主要 backbone,最後預測出每個關鍵點的 score, x_offset, y_offset以及num_nb個鄰居的x_offset, y_offset
import torch
import torch.nn as nn
class Pip_resnet18(nn.Module):
def __init__(self, resnet, num_nb, num_lms=68, input_size=256 ):
super(Pip_resnet18, self).__init__()
self.num_nb = num_nb # 要預測鄰居的數量
self.num_lms = num_lms # 一共要預測幾個點
self.input_size = input_size # 輸入照片大小
self.conv1 = resnet.conv1
self.bn1 = resnet.bn1
self.maxpool = resnet.maxpool
self.sigmoid = nn.Sigmoid()
self.layer1 = resnet.layer1
self.layer2 = resnet.layer2
self.layer3 = resnet.layer3
self.layer4 = resnet.layer4
# 定義預測 score
self.cls_layer = nn.Conv2d(512, num_lms, kernel_size=1, stride=1, padding=0)
# 定義預測此關鍵點的 X offset
self.x_layer = nn.Conv2d(512, num_lms, kernel_size=1, stride=1, padding=0)
# 定義預測此關鍵點的 Y offset
self.y_layer = nn.Conv2d(512, num_lms, kernel_size=1, stride=1, padding=0)
# 定義鄰居關鍵點的 X offset, 特別注意一共有num_nb個鄰居,所以應該要預測num_nb張圖
self.nb_x_layer = nn.Conv2d(512, num_nb*num_lms, kernel_size=1, stride=1, padding=0)
# 定義鄰居關鍵點的 Y offset, 特別注意一共有num_nb個鄰居,所以應該要預測num_nb張圖
self.nb_y_layer = nn.Conv2d(512, num_nb*num_lms, kernel_size=1, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = F.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
score = self.cls_layer(x)
x_offset = self.x_layer(x)
y_offset = self.y_layer(x)
nb_x = self.nb_x_layer(x)
nb_y = self.nb_y_layer(x)
return score, x_offset, y_offset, nb_x, nb_y
因為多了 Neighbor 的點要去預測,所以在dataloader 中的 __getitem__需要多撈 Nighbor 的 x_offset, y_offset。另外,self.net_stride = 32
def __getitem__(self, index):
img_name, target = self.imgs[index]
img = Image.open(os.path.join(self.root, img_name)).convert('RGB')
# 假設我們這裡有 data transform處理
img, target = translate_function(img, target)
img = random_occlusion(img)
target_map = np.zeros((self.num_lms, int(self.input_size/self.net_stride), int(self.input_size/self.net_stride)))
target_local_x = np.zeros((self.num_lms, int(self.input_size/self.net_stride), int(self.input_size/self.net_stride)))
target_local_y = np.zeros((self.num_lms, int(self.input_size/self.net_stride), int(self.input_size/self.net_stride)))
target_nb_x = np.zeros((self.num_nb*self.num_lms, int(self.input_size/self.net_stride), int(self.input_size/self.net_stride)))
target_nb_y = np.zeros((self.num_nb*self.num_lms, int(self.input_size/self.net_stride), int(self.input_size/self.net_stride)))
target_map, target_local_x, target_local_y, target_nb_x, target_nb_y = gen_target_pip(target, self.meanface_indices, target_map, target_local_x, target_local_y, target_nb_x, target_nb_y)
其中 gen_target_pip 為下方 get data 的涵式,可以看到他根據meanface_indices的順序去取最近的鄰居的座標
def gen_target_pip(target, meanface_indices, target_map, target_local_x, target_local_y, target_nb_x, target_nb_y):
num_nb = len(meanface_indices[0])
map_channel, map_height, map_width = target_map.shape
target = target.reshape(-1, 2)
assert map_channel == target.shape[0]
for i in range(map_channel):
mu_x = int(floor(target[i][0] * map_width))
mu_y = int(floor(target[i][1] * map_height))
mu_x = max(0, mu_x)
mu_y = max(0, mu_y)
mu_x = min(mu_x, map_width-1)
mu_y = min(mu_y, map_height-1)
target_map[i, mu_y, mu_x] = 1
shift_x = target[i][0] * map_width - mu_x
shift_y = target[i][1] * map_height - mu_y
target_local_x[i, mu_y, mu_x] = shift_x
target_local_y[i, mu_y, mu_x] = shift_y
for j in range(num_nb):
nb_x = target[meanface_indices[i][j]][0] * map_width - mu_x
nb_y = target[meanface_indices[i][j]][1] * map_height - mu_y
target_nb_x[num_nb*i+j, mu_y, mu_x] = nb_x
target_nb_y[num_nb*i+j, mu_y, mu_x] = nb_y
return target_map, target_local_x, target_local_y, target_nb_x, target_nb_y
簡單講 Loss , score 可以為 cross_entropy 甚至更簡單的 L1 即可! 而其他 offset 的預測則只要使用 L1 就好。
今晚我們介紹完了 Hourglass 的實作,希望大家都能夠建立出自己的 Facial landmark AI model!我們下個章節見!
1.https://github.com/jhb86253817/PIPNet/tree/master


 iThome鐵人賽
iThome鐵人賽